Silent speech recognition is a promising technology that decodes human speech without requiring audio signals, enabling private human-computer interactions. In this paper, we propose Watch Your Mouth, a novel method that leverages depth sensing to enable accurate silent speech recognition. By leveraging depth information, our method provides unique resilience against environmental factors such as variations in lighting and device orientations, while further addressing privacy concerns by eliminating the need for sensitive RGB data. We started by building a deep-learning model that locates lips using depth data. We then designed a deep learning pipeline to efficiently learn from point clouds and translate lip movements into commands and sentences. We evaluated our technique and found it effective across diverse sensor locations: On-Head, On-Wrist, and In-Environment. Watch Your Mouth outperformed the state-of-the-art RGB-based method, demonstrating its potential as an accurate and reliable input technique.
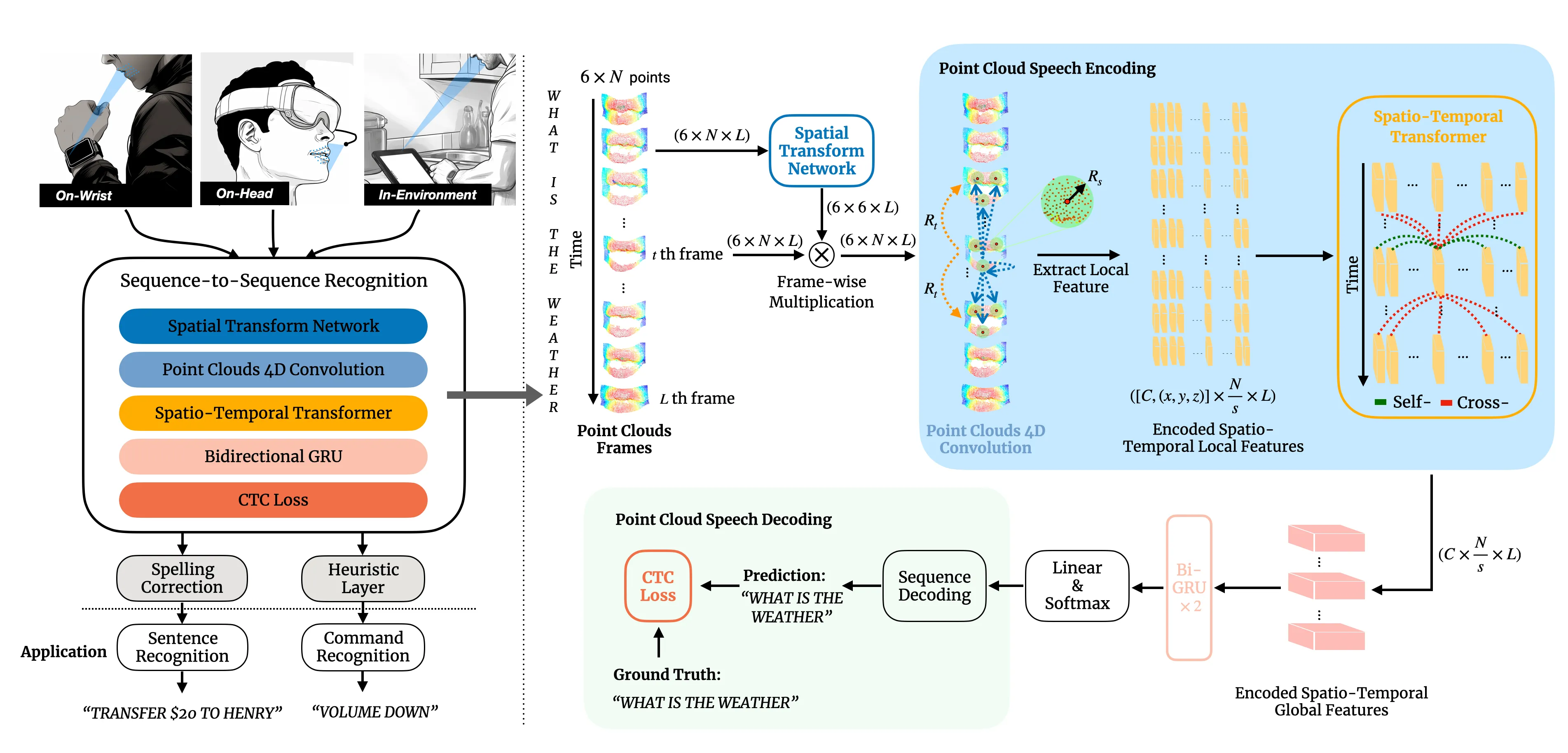
System Overview
Figure 1: Left: Watch Your Mouth performs silent speech recognition through depth sensing at three different sensor locations: On-Wrist, On-Head, In-Environment; Right: The deep learning architecture of Watch Your Mouth, N represents the number of points in each point cloud frame, L signifies the length of the video, 𝑠 denotes the sampling rate, 𝑅𝑠 and 𝑅𝑡 refer to the spatial radius and temporal kernel size, respectively. 𝐶 is the dimension of the transformer layer in this pipeline.
Data Collection
Figure 2: We recruited a group of 10 participants (6 Females) to participate in our data collection process. Additionally, 5 of the participants wore glasses, and 2 participants were native English speakers without any discernible accents. Sequentially in the data collection, we placed our depth sensing device at three distinct sensor locations: On-Wrist (left), On-Head (middle), and In-Environment (right).
You can find the point clouds sentence dataset from here: Sentence Dataset.
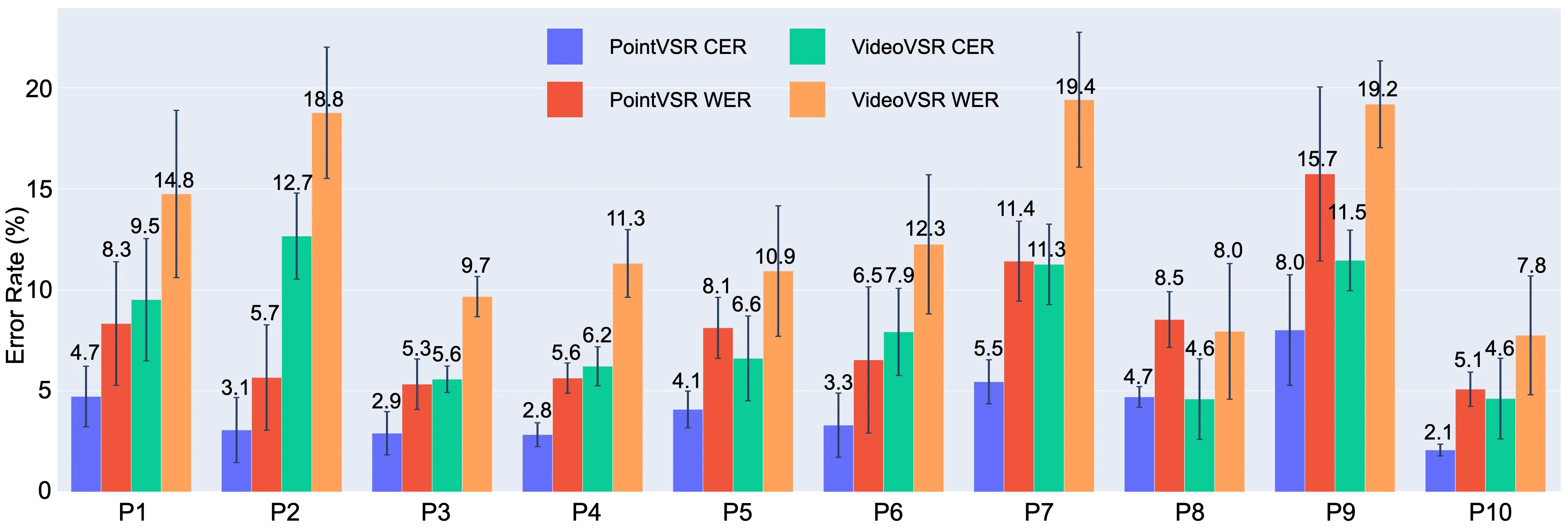
System Evaluation
Figure 3: CER and WER from the within-user performance evaluation with error bars indicating standard deviations across folds.
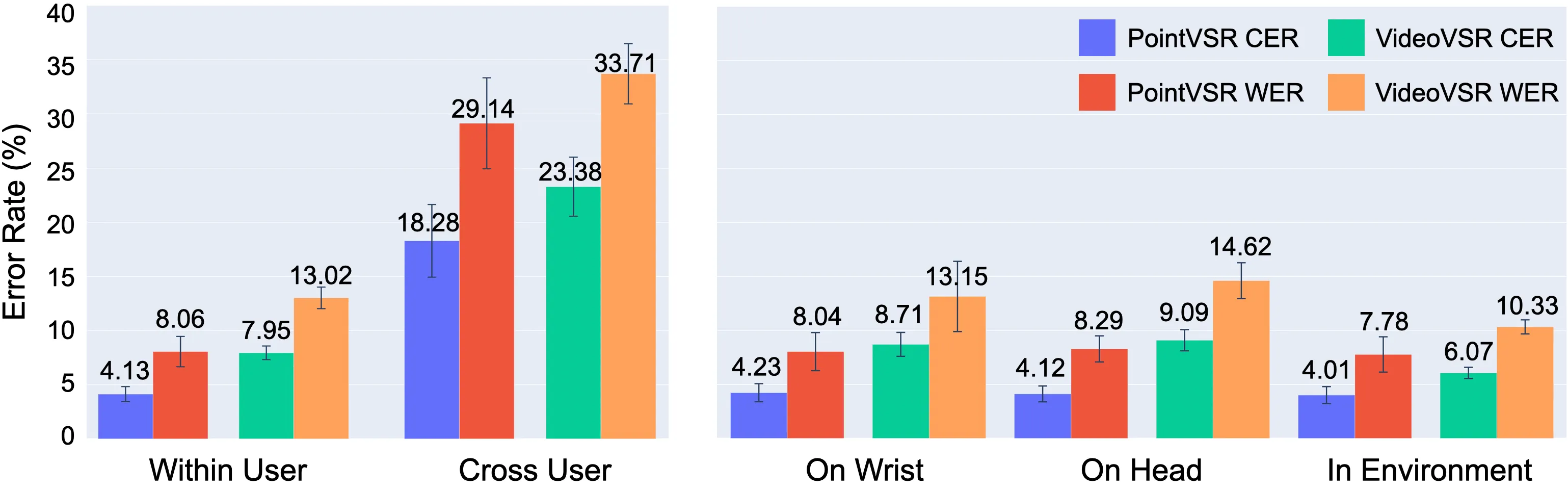
Figure 4: Comparison of sentence recognition performances with different sensing modalities/models, breaking down on within- and cross-user train-test methods (left), and on sensor location (right). Error bars indicate standard deviations across participants.
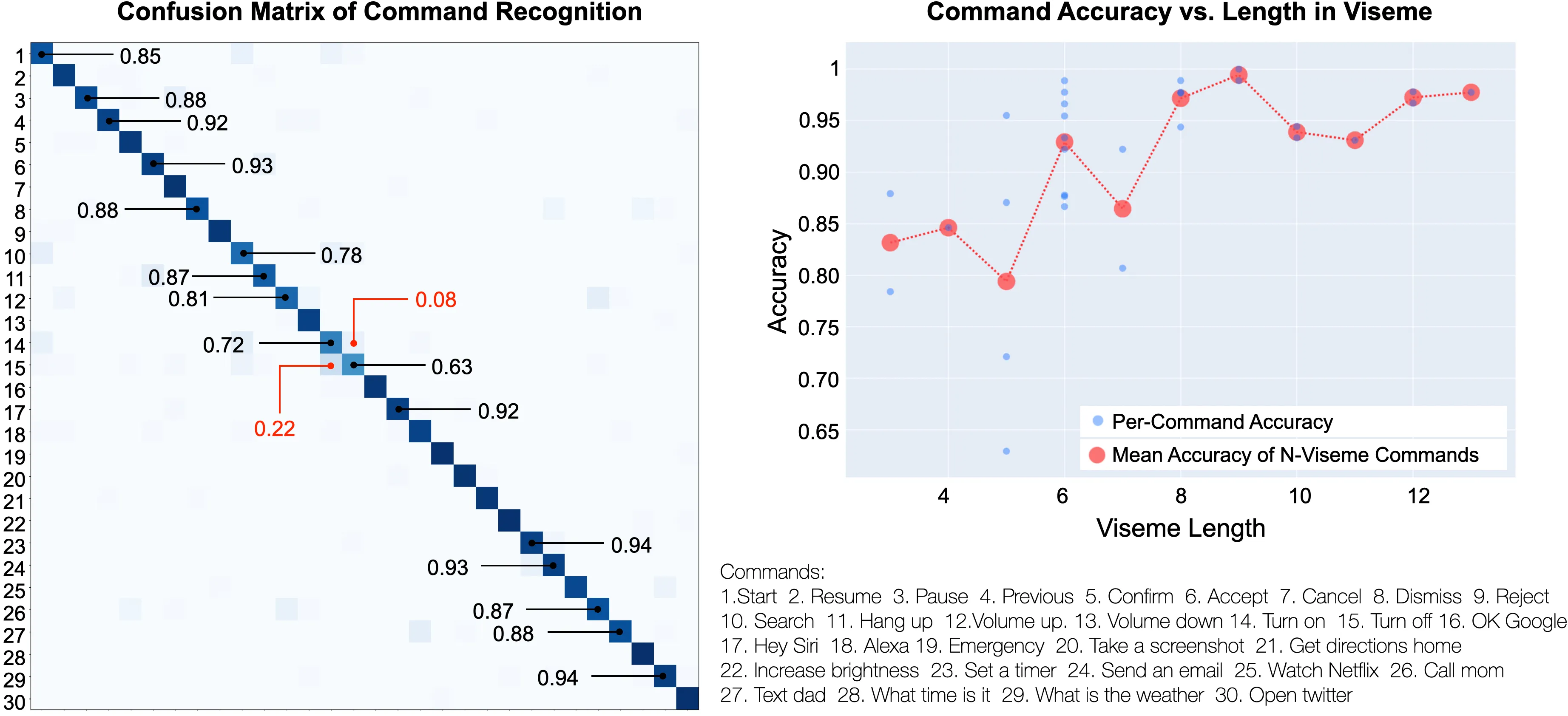
Figure 5: Left: Confusion Matrix of 5-fold within-user command recognition across 30 distinct commands. Accuracy is over 95% unless indicated otherwise. Right: Correlations between viseme length and recognition accuracy.
To ensure compatibility between PyTorch and CUDA, you should first determine the version of CUDA installed on your system. You can do this by running the following command in your terminal:
nvcc --version
Once you have your CUDA version, visit the PyTorch official installation guide to find the PyTorch version that corresponds to your CUDA version, for example:
Compile the Pointnet2 CUDA layers with the following code:
cd WatchYourMouth/modulespip install .
STEP3: Download the Dataset
Please download the dataset HERE and store it in the directory.
STEP4: Start Training
Update the dataset path to the location where your dataset is stored in this line, and start training with the following code:
cd WatchYourMouth/python train_sentences.py
Citation
@inproceedings{wang2024watch, title={Watch Your Mouth: Silent Speech Recognition with Depth Sensing}, author={Wang, Xue and Su, Zixiong and Rekimoto, Jun and Zhang, Yang}, booktitle={Proceedings of the CHI Conference on Human Factors in Computing Systems}, pages={1--15}, year={2024}}